Modelisation MCD, MLD, MPD¶
1. Définitions¶
Un système de gestion de base de donnée (SGBD)¶
Une base de donnée est un logiciel qui permet de stocker et retrouver l’intégralité des données en rapport avec un thème ou une activité. Elle est généralement au centre de dispositifs informatiques de collecte et de stockage d’information. Un système de gestion de base de donnée est une suite de logiciel qui permettent de stocker et de retrouver l’information dans la base.
Elle sert à (SOSI) :
- Stocker des données
- Organiser des données
- Structurer des données
- Interroger les données
On change de BDD en fonction de la nature des données ou des moyens d'y accéder.
Modèles logiques de donnée (MLD)¶
La typologie des bases de données peuvent être différentes selon : - les usages (données pour mobiles, données pour usage client/serveur) - La licence d'utilisation - Si elles respectent ou non des principes (ACID)
Il questionne le réel Modeliser une bdd, c'est transfromer le réel en Bdd fonctionnelle (qui répond à nos besoins)
Les principes ACID (Atomicité, Cohérence, Isolation, Durabilité) garantissent le traitement fiable des transactions en base de données, assurant l'intégrité et la sécurité des données. Elles garantissent qu'une transaction informatique est exécutée de façon fiable.
Clés/valeurs¶
Les bases de données clé/valeurs enregistrent une simple clé à une ou plusieurs valeurs.
Exemple :
| Clé | Valeurs |
|---|---|
| 01 | Bon état |
| 02 | Mauvais état |
| 03 | Mort |
- Time serie databases¶
Les bases de données « time series », (en français « séries chronologiques ») permettent de retracer l’évolution d’une valeur au cours du temps.
- Base de donnée en graphe¶
Les bases de données en graphe permettent d’interroger des données sous forme de graphe : les éléments sont enregistrés sous formes de noeuds et de relations.
- Orienté documents¶
Les bases de données orientées documents enregistrent les informations au sein de « documents », qui contiennent les données semi-structurées de chaque entité.
- Système de gestion de base de donnée relationnel¶
Les système de gestion de base de donnée relationnel sont les plus fréquemment utilisées des bases de donnée.
Concepts principaux des systèmes de gestion de base de donnée relationnels¶
- Schema de base d'une BDD relationnelle¶
- Dans un système de gestion de base de donnée relationnel, les informations sont conservées au sein de tables.
- Au sein de chaque table, nous retrouvons les enregistrements.
- Les tables peuvent être mise en relation les unes aux autres.
- Cette mise en relation est effectuée en définissant des clés qui servent de référence dans les tables.
mais aussi
IMPORTANT
- Lors de la conception, d’une base de donnée, les données calculées ne sont pas conservées : elles sont recalculées. Elles seront décrites par le modèle conceptuel des traitements (MCT).
- Les tables correspondent à des entités uniques, qui partagent les mêmes caractéristiques. Lorsque des attributs se répètent, il est possible de les extraire dans une table séparée et de créer des relations entre les tables (et les enregistrements).
- Les tables¶
- Les tables enregistrent les éléments qui ont les mêmes caractéristiques.
- Chaque table définit un certain nombre de champs : des colonnes qui sont typées
- Une table est peuplée d’enregistrements
IMPORTANT
Le principe de création d’une table est qu’aucune donnée ne soit redondante : une information identique ne devrait pas être stockée à deux endroits. Si c’est le cas, il est fort probable qu’elle puisse être extraite et stockée dans sa propre table.
- Les relations¶
Les tables peuvent être mises en relation les unes aux autres.
- une liste de ville peuvent appartenir à un pays
- un animal peut être d’une certaine espèce
- Clés primaires¶
Les clés primaires sont des identifiants uniques des enregistrements. Par définition, une clé unique doit être... unique pour tous les enregistrements de la table. Elles peuvent porter sur une seule colonne, comme pour plusieurs. Dans ce deuxième cas, la contrainte d’unicité porte sur la combinaison des deux colonnes.
- Clés étrangères¶
Lorsque des relations sont créées entre des tables d’un système de gestion de base de donnée relationnel, la table qui effectue la référence contient une relation vers la clé primaire de la table référencée. Cette colonne « de relation » est appelée une clé étrangère.
Modélisation des données au sein d’un SGBDR¶
La modélisation de la base de donnée est une étape importante pour construire celle-ci.
Cette étape donne lieu à des questions : - savoir dans quelle table placer certaines colonnes (par exemple, l’adresse de livraison se met dans la table des clients ou dans la table des commandes ?) - décider des tables de jonction intermédiaires (par exemple, la table des interprétations qui est indispensable entre les tables des films et la table des acteurs).
La modélisation MERISE (Méthode d’Étude et de Réalisation Informatique pour les Systèmes d’Entreprise) élaborée en France en 1978 [Tardieu et al.], qui permet notamment de concevoir un système d’information d’une façon standardisée et méthodique.
Modèle Conceptuel, Logique et Physique des données¶
3 étapes
Modèle Conceptuel de Données (MCD)¶
- Le modèle conceptuel de données s’attache à décrire les entités et leurs relations. Les relations sont nommées généralement par des verbes, et les entités par le nom d’un objet.
- Chaque entité comporte des attributs. Chaque attribut doit être rempli pour chaque entité. Un identifiant est généralement également mentionné.
- Les relations peuvent également comporter des attributs.
- Les cardinalités des relations sont également décrites.
Modèle Logique de Données (MLD)¶
Le modèle logique de données reprend le contenu du MCD précédent, mais précise également la manière dont ce modèle sera implémenté. Lorsque le système utilise un SGBDR, on retrouve à ce stade la liste des tables et des colonnes, la mention des clés étrangères, etc.
Modèle Physique de Données (MPD ou LDD)¶
Le modèle physique de données décrit de manière précise la manière dont le MLD sera implémenté. Il explique, par exemple, les choix d’un logiciel de SGBDR.
Construire un MCD¶
entité = Classe d 'objet - objets - table - éléments rééls d'un objet matériel ou immatériel
propriété = attribut - les champs - Caractériqtiques de entités séparées et identifiées
association = relation - lien qui est fait entre les entités
client postgresql = Pgadmin, ligne de commande sur wsl ou terminaux
Cast = transtypage ou coercition
Cardinalité = la définition, l'évaluation des liens entre les entités.
Les entités¶
Une entité est la représentation d’un objet matériel ou immatériel. Elle est une population d’individus homogène, c’est à dire un ensemble de données cohérentes ayant des caractéristiques simples.
Une propriété (ou attribut) est une donnée élémentaire relative à une entité. On ne considère que les propriétés qui ont du sens dans le contexte abordé. Il n’y a pas de propriété facultative : chacune devra être renseignée.
2 manières textuelles d'écrire les entité et leurs propriétés:
1 2 3 | |
L’identifiant est une propriété ou groupe de propriétés qui sert à identifier une entité. Il est choisi de manière à être unique : deux occurrences d’une entité ne peuvent pas avoir le même identifiant.
Par convention, l’identifiant est la première propriété. Si l’identifiant est composé de plusieures propriétés, on préfixe le nom de ces propriétés par un caractère de soulignement (_).
Les associations¶
Une association (ou relation) est une liaison sémantique entre entités.
L’association peut être le lien entre : 1. entité reliée à elle-même : la relation est dite réflexive, 2. entités : la relation est dite binaire (ex : une usine ‹ est implantée › dans un pays), 3. plus rarement 3 ou plus : ternaire, voire de dimension supérieure. En fait, si une relation a 3 points d’attache ou plus, on peut réécrire la relation en transformant la relation en table et en transformant les liens en relations.
Cette description sémantique est enrichie par la notion de cardinalité, celle-ci indique le nombre minimum(généralement 0 ou 1) et maximum (généralement 1 ou n) de fois où une occurrence quelconque d’une entité peut participer à une association.
EXEMPLE :
1 2 3 4 5 | |
1 2 3 | |
Le nom des relations est parfois remplacé par DF, pour « Dépendance fonctionnelle » lorsqu’une des cardinalités d’une association binaire est 1. En effet, dans ce cas, le nom disparaitra lors de la conversion vers un MLD.
Normalisation d'un MCD¶
Le but essentiel de la normalisation est d’éviter les anomalies transactionnelles pouvant découler d’une mauvaise modélisation des données et ainsi éviter un certain nombre de problèmes potentiels tels que les anomalies de lecture, les anomalies d’écriture, la redondance des données et la contreperformance.
Des attributs qui se suffisent à eux mêmes¶
Chaque attribut doit être complet, se suffire à lui-même. Il ne doit pas pouvoir se décomposer en plusieurs autres attributs.
IMPORTANT
- Une date est un seul attribut elle ne se décompose pas
- Exemple du nom et prénom comme 1 seul attribut. Les deux éléments peuvent être différenciés.
Les attributs doivent avoir une certaine forme de persistance : ils ne doivent pas changer au fil du temps. SI ils sont amener à changer, on pourrait les retrouver en tant que propriété 'atteribut) d'une table de relation comme la fonction d'une personne.
Des ensembles d’attributs cohérents¶
Les règles de normalisation stipulent que chaque attribut doit se référer à l’objet qui est référencé, et uniquement à lui.
Ainsi, si un attribut dépend d’un autre attribut, alors il est sans doute intéressant de promouvoir cet attribut comme un nouvel identifiant dans une nouvelle entité, et de lui accoler cet attribut.
EXEMPLE :
| Numéro de commande | Produit | Paquet | Poids du paquet | Date d’envoi du paquet |
|---|---|---|---|---|
| 1 | 123456 | ABC456LESS | 5kg | 15/01/2022 |
| 1 | 456798 | ABC456LESS | 5kg | 15/01/2022 |
| 1 | 789123 | ABC456LESS | 5kg | 15/01/2022 |
| 1 | 456789 | GHIDD456LES | 3kg | 15/03/2022 |
=>
| Numéro de commande | Produit | Paquet |
|---|---|---|
| 1 | 123456 | ABC456LESS |
| 1 | 456798 | ABC456LESS |
| 1 | 789123 | ABC456LESS |
| 1 | 456789 | GHIDD456LES |
ET
| Paquet | Poids du paquet | Date d’envoi du paquet |
|---|---|---|
| ABC456LESS | 5kg | 15/01/2022 |
| ABC456LESS | 5kg | 15/01/2022 |
| ABC456LESS | 5kg | 15/01/2022 |
| GHIDD456LES | 3kg | 15/03/2022 |
Outils de modélisation¶
Mocodo ([http://www.mocodo.net]) Looping
Convertir un MCD en MLD¶
le MLD reprend le contenu du MCD en précisant la manière dont ce modèle sera implémenté.
Le MLD décrit : - les tables, - les champs contenus dans les tables, - les clés primaires - et les clés étrangères.
Le MLD peut être décrit de manière linéraire de la manière suivante : - chaque ligne représente une table, - le nom de la table qui est écrit en premier, - les champs sont listés entre parenthèses et séparés par des virgules, - les clés primaires sont soulignées et placées au début de la liste des champs ; - les clés étrangères sont préfixées par un dièse.
1 2 3 4 | |
Règles de conversion¶
-
Identification des tables et des champs
- Une entité du MCD devient une table (ou relation).
- L’identifiant d’une entité devient la clé primaire de la table
- Les autres propriétés n’étant pas comprises dans l’identifiant deviennent les champs de la table (ou attributs de la relation).
-
Gestion des relations 1:N
Une association de type 1:N (c’est à dire qui a les cardinalités maximales positionnées à 1 d’une côté de l’association et à N de l’autre côté) se traduit par la création d’une clé étrangère dans la relation correspondante à l’entité côté 1.
Cette clé étrangère référence la clé primaire de la relation correspondant à l’autre entité.
Exemple :
1 2 | |
- Gestion des relations N:N
Une association de type N:N (c’est à dire qui a les cardinalités maximales positionnées à N des 2 côtés de l’association) se traduit par la création d’une table dont la clé primaire est composée des clés étrangères référençant les relations correspondant aux entités liées par l’association.
Les éventuelles propriétés de l’association deviennent des attributs de la relation.
Exemple :
1 2 3 | |
Le langage SQL, et PostgreSQL¶
- SQL est une norme,
- PostgreSQL est un logiciel de système de gestion de base de donnée relationnel, qui applique une grande partie des éléments de cette norme, mais ajoute également d’autres fonctionnalités qui ne sont pas, ou pas encore, normées.
Le langage et la norme SQL, implémentation dans PostgreSQL¶
Le but du langage SQL est de communiquer avec un SGBDR : l’utilisateur lance des requêtes au SGBDR, qui lui renvoie une réponse. Ces requêtes suivent une syntaxe particulière, qui a pour but d’être lisible et compréhensible par l’humain (human readable).
Types de requêtes (DDL,DML,DCL,TCL)¶
-
Les requêtes DDL, pour data definition language, permettent de manipuler les objets de la base de donnée : création de tables, de vues, d’index, etc. Elles commencent par les mots-clés suivants : CREATE, ALTER, DROP
-
Les requêtes DML, pour data manipulation language, permettent d’insérer ou de modifier des enregistrement dans les tables. Elles commencent par les mots clés INSERT, UPDATE, DELETE et SELECT pour visualiser les données
-
Les requêtes DCL pour data control language permettent de modifier les droits d’accès aux données. Elles commencent par les mots-clés GRANT, REVOKE.
-
Les requêtes TCL contrôlent les transactions. Les mots-clés correspondants : BEGIN TRANSACTION, COMMIT, ROLLBACK.
PostgreSQL et son écosystème¶
documentation¶
- EN https://www.postgresql.org/docs/
- FR https://docs.postgresql.fr/
CAST¶
Les objets de types CAST sont des déclarations de possibilité de transtypage additionnelles
Le répertoire catalog¶
Le répertoire contient les méta-données relatives aux objets manipulés dans la base de donnée. Par exemple, à chaque fois qu’une table est créée dans la base de donnée, un enregistrement est ajouté dans ce catalogue.
Event triggers¶
Ce répertoire liste les événements enregistrés dans la base de donnée.
Extensions¶
Ce répertoire liste les extensions ajoutées à la base de donnée. Les extensions ajoutent de nouvelles fonctionnalités. Postgis files_fdw, postgres_fdw , ogr_fdw
Foreign Data Wrapper¶
Les Foreign Data Wrapper sont une possibilité de connecter une source de donnée externe et de la traiter comme une base de donnée. Il est par exemple possible de « déclarer » dans la base de donnée un fichier shapefile, une base de donnée mysql, ou un fichier CSV, puis d’interroger en langage SQL.
Schémas¶
Le schéma est une manière d’organiser une base de donnée de manière logique.
- les tables de donnée ;
- les vues, dont nous parlerons plus loin ;
- les séquences, qui seront également abordées plus loin.
- les fonctions déclarées, tables et types, qui ne seront pas abordées ici.
Outre une meilleur logique, cela permet de mieux exploiter la gestion des accès (ouvrir les droits sur un schéma à un utilisateur), ou de gérer plus finement les sauvegardes (éviter de contenir dans un fichier de sauvegarde des données créées par une extension, comme la liste des systèmes spatiaux).
Types de données¶
https://www.postgresql.org/docs/12/datatype.html
En SQL, chaque colonne se voit attribuer un type de donnée. Ces types sont, par exemple, text ou varchar pour du texte, int pour des entiers, etc. À chaque type de donnée correspond des restrictions et des fonctionnalités associées.
À chaque type correspond des fonctionnalités, comme : - des fonctions natives de PostgreSQL, comme la possibilité d’arrondir un nombre (ROUND), de placer un texte en majuscule (UPPER), ...
Note : les fonctions sont fortement typées en PostgreSQL.
- le passage d’un type à un autre peut être effectué automatiquement par PostgreSQL lorsque cela est nécessaire et permis. Par exemple, PostgreSQL permet de transformer la chaine de texte '1' en entier 1, mais renverra une erreur si l’on essaye de transformer une autre chaine, comme hello. Cette opération est appelé cast en anglais, transtypage ou coercition en français.
Création d’objets DDL¶
CREATE DATABASE name; CREATE SCHEMA name ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Insertion d’enregistrements DML¶
En synthèse, la requête définit une table d’entrée et la liste des colonnes qui vont être spécifiées. Ensuite, une liste des valeurs à insérer est enregistrée, délimitées par des parenthèses et une virgule. À l’intérieur de chaque enregistrement, les valeurs sont séparées par des virgules et données dans l’ordre de la déclaration des colonnes. Exemple :
1 2 | |
1 2 3 4 5 6 7 | |
Mise à jour et suppression de données DML¶
Les mises à jour peuvent être effectuées avec la commande UPDATE et supprimées avec la commande DELETE
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Visualisation des données (requêtes SELECT) DML¶
Projection (sélection de colonnes)¶
Nous pouvons choisir quelles colonnes, ou même résultat d’opération, apparaissent dans la requête SELECT. Cette possibilité s’appelle la « projection » : Select normal avec ou sans toutes les colonnes et rajout de calcul si besoin
Sélection de lignes¶
Les enregistrements peuvent être filtrés en utilisant la clause WHERE : Le contenu de la clause WHERE doit renvoyer un booléen (un VRAI/FAUX). Il est également possible d’insérer des formules ou des fonctions, et également de combiner les clauses avec les opérateurs OR et AND
Tri de colonnes¶
Les mots-clés ORDER BY permettent d’ordonner les résultats
Limites de résultats¶
Il est possible de « paginer » les résultats, en indiquant le premier enregistrement à renvoyer, et le nombre de ceux-ci à afficher. Pour augmenter les performances, il est conseillé de limiter tant les résultats que le nombre de colonnes à indiquer.
1 2 3 4 5 | |
Fonctions d’agrégation¶
Les fonctions d’agrégation permettent d’effectuer un calcul sur plusieurs enregistrements, et de retourner un unique résultat. Elles permettent, entre autres, de calculer :
- la moyenne d’une colonne (AVG) ;
- le nombre d’enregistrement d’une colonne (COUNT) ;
- le maximum (MAX) ou minimum (MIN) ou la somme (SUM) d’une colonne.
Ces calculs peuvent être regroupés en utilisant la clause GROUP BY. Cette clause regroupe alors les résultats selon les informations décrites par cette clause : la fonction d’agrégation n’est opérée que sur ce sous-groupe de résultats.
Les fonctions d’agrégation ne peuvent pas être exécutées dans une clause WHERE : pour filtrer selon les résultats agrégés, il faut avoir recours à la clause HAVING. Cette clause HAVING fonctionne de la même manière que WHERE : elle contient une condition qui filtre les résultats qui n’y correspondent pas.
- AVG : moyenne
- SUM : somme
- COUNT : nombre
- MIN et MAX : Maximum et minimum
Il est possible également d’utiliser un count uniquement sur les valeurs uniques : COUNT(distinct id) ne comptabilisera qu’un seul identifiant.
1 2 3 4 5 | |
| pays_id | sum |
|---|---|
| 3 | 623404 |
Jointures¶
re-créer les relations entre les tables au moyen de requêtes multitables
Il est également possible d’utiliser des clauses JOIN ... ON ... pour effectuer des jointures, ce qui est fréquemment jugé plus élégant.
Dans PostgreSQL, placer la condition de la jointure dans la clause JOIN ... ON ... ou dans la clause WHERE est équivalent : les deux méthodes ont la même rapidité (le planificateur de requête les traitera de manière identique). Notez qu’il existe une latéralité aux jointures
La clause ON peut être remplacée par une clause USING lorsque les colonnes à associer comportent le même nom dans les deux tables : USING (a, b) est un raccourci pour ON left_table.a = right_table.a AND left_table.b = right_table.b. La clause NATURAL est un autre raccourci pour un USING où toutes les colonnes qui comporteraient le même nom effectueraient l’association. Attention, si aucune colonne ne comporte le même nom, NATURAL est l’équivalent de ON TRUE (chaque enregistrement de la table de gauche est associée à tous les enregistrements de la table de droite).
Sous-requêtes¶
Sous-requête dans une clause JOIN¶
Jusqu’ici, les jointures ont rassemblé deux tables existantes. Il est également possible d’effectuer les jointures à partir d’autres requêtes. Dans ce cas, les colonnes de résultats sont utilisées pour effectuées la jointure.
Sous-requête dans la projection (clause SELECT) ou dans les conditions WHERE¶
Une sous-requête peut également être effectuée dans une autre partie de la requete, comme la clause SELECT ou WHERE. Dans ce cas, la jointure, si nécessaire, est effectuée au moyen d’une condition dans la clause WHERE de la sous-requête. Dans ce cas, la sous-requête ne doit renvoyer qu’une seule colonne et une seule ligne de données. Cette colonne est considérée comme le résultat qui sera affiché dans la clause SELECT ou pris en compte dans la clause WHERE.
Expression de sous-requêtes : EXISTS, IN, SOME et ANY¶
Des mots-clés supplémentaires permettent de travailler avec ces fonctions : EXISTS, IN, SOME et ANY. Ces méthodes reçoivent une sous-requête en argument.
EXISTS EXISTS reçoit une sous-requête en argument.¶
TRUE est retourné si la sousrequête renvoie au moins une ligne de donnée, FALSE si aucune ligne n’est renvoyée.
IN et NOT IN¶
L’expression IN prend en argument : - un valeur ou une colonne ; - une sous-requete qui doit renvoyer une seule colonne.
L’expression retourne TRUE si la valeur ou la colonne se trouve dans la liste des valeurs ou des colonnes renvoyées par la sous-requête. L’expression NOT IN, quant à elle, renvoie TRUE si aucune valeur indiquée ne se retrouve dans la liste des résultats de la sous-requête.
Note : la requête IN réalise quasiment le même travail que la requête EXISTS ci-dessus. À priori, il peut exister des différences de performances dans certains contextes : la sous-requête dans la clause IN pourrait forcer postgresql à collecter une liste de données (ici, les identifiants de pays) longue, ce qui consommerait de la mémoire. Tandis que la requête EXISTS pourrait, elle, être répétée plusieurs fois pour chaque ligne de la requête principale. Cependant, le planificateur de requête de PostgreSQL est généralement suffisamment intelligent pour choisir le plan d’exécution le plus rapide.
ANY et SOME (ANY et SOME sont deux synonymes.)¶
Ces expressions sont composées comme suit : - une expression (une valeur ou une colonne, entre autre) ; - un opérateur de comparaison : par exemple, < (strictement plus petit que), >= (plus grand que ou égal), ... ; - et une liste de valeur à comparer, qui peut provenir d’une sous-requête qui ne renvoie qu’une seule colonne de résultats. ANY (et SOME) renverra TRUE si au moins une ligne dans la liste de résultat (la sous-requête) renvoie TRUE lorsqu’il est comparé à la donnée comparée.
ALL¶
L’expression ALL fonctionne comme ANY : elle se composent : - d’une autre expression (valeur ou colonne) ; - d’un opérateur de comparaison ; - et d’une liste de valeur à comparer qui proviennent d’une sous requête qui ne renvoient qu’une seule colonne de résultats.
L’expression retourn TRUE si toutes les valeurs de la liste de valeurs répond TRUE à la comparaison effectuée, ou si la liste des valeur à comparer est vide.
Requêtes UNION¶
Les requêtes UNION permettent d’associer d’effectuer deux requêtes différentes et d’associer leur résultat. Dans l’exemple ci-dessous, nous listons le nom des villes et des pays, ainsi que leur identifiant :
1 2 3 4 5 | |
Requêtes WITH (Common Table Expression)¶
WITH est un moyen de déclarer des requêtes pour une ré-utilisation dans une requête plus large. L’on peut comprendre ce mécanisme comme un moyen de définir une requête temporaire. Nous pouvons ré-écrire la requête ci-dessus (calcul de la proporition de population de la ville dans celle de son pays) en utilisant une clause WITH :
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
WINDOW¶
Les fonctions WINDOW permettent d’effectuer un calcul à travers plusieurs enregistrements qui sont reliés à l’enregistrement courant. Ces fonctions peuvent être comparables au type de calcul qui peuvent être effectués à l’aide de fonction d’agrégation. Cependant, les fonctions window ne créent pas de regroupement dans une seule ligne : chacune peut conserver ses attributs. Ces informations peuvent être donc affiché dans la même requête.
PostGIS¶
...
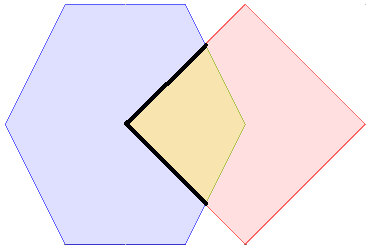
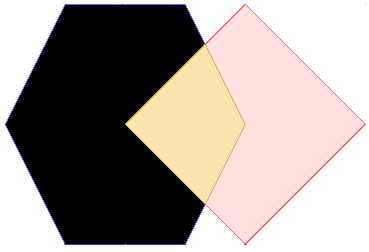
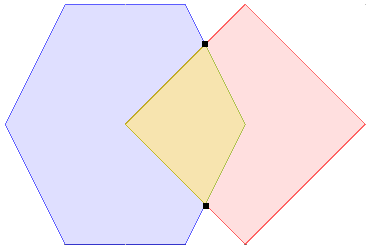
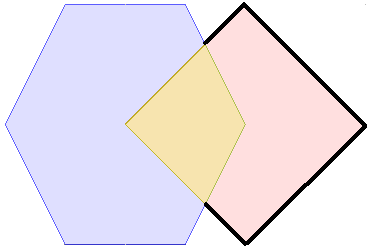
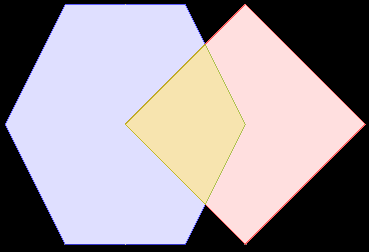
Le modèle d’intersection spatiales¶
Pour caractériser les interactions d’objets géographiques les uns avec les autres, un modèle d’intersection a été créé. Il décrit la manière dont les objets géographiques peuvent s’entrecroiser les uns avec les autres.
Plus important, il définit 10 verbes anglais qui définissent précisément des relations spatiales : intersects, touches, ...
| 9IM | Interior | Boundary | Exterior |
|---|---|---|---|
| Interior | 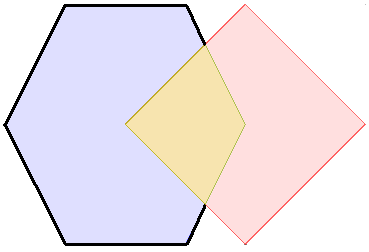 |
 |
 |
| Boundary | 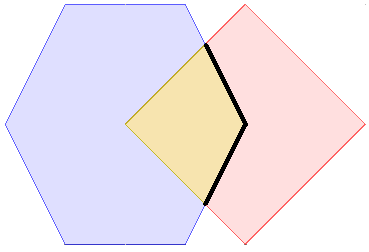 |
 |
|
| Exterior | 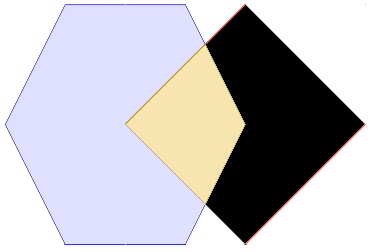 |
 |
 |
Prédicats spatiaux¶
- Equals : TFFFF
- Disjoint : FFFF*** ;
- Touches : FT* ou FT ou FT****
- Covers : T*FF ou TFF ou TFF ou TFF*
- Intersects : T* ou T* ou T ou T**
- Within : TFF**
- CoveredBy : TFF ou TF**F ou FTF ou FTF
- Crosses : TT* ou TT* ou 0** (0 concerne un point)
- Overlaps : TTT, 1TT
Des prédicats spatiaux sont définis à partir de ces 9 situations. Ils peuvent représentés de manière linéaires (sur une seule ligne), où T impose que cette situation soit rencontrée, F qu’elle ne soit pas rencontrée (false), et * exprime une indifférence. On peut aussi indiquer que le croisement doit concerner des points (0), des lignes (1) ou une aire (2).
ACID¶
- Atomicité L'atomicité garantit qu'une transaction est traitée comme une unité unique et indivisible. Cela signifie que toutes les opérations d'une transaction doivent être achevées entièrement ou pas du tout. Si une partie de la transaction échoue, le système annule l'ensemble de la transaction, ce qui garantit qu'aucune mise à jour partielle n'est effectuée.
Exemple : Dans une transaction bancaire, l'atomicité garantit que les deux opérations sont menées à bien lorsque l'argent est débité d'un compte et crédité sur un autre. Si le débit ou le crédit échoue, la transaction est entièrement annulée.
- Cohérence La cohérence garantit qu'une transaction fait passer la base de données d'un état valide à un autre tout en respectant des règles ou des contraintes prédéfinies. Après avoir effectué une transaction, les données doivent satisfaire à toutes les règles d'intégrité de la base de données.
Exemple : Dans le domaine bancaire, la cohérence garantit que le solde total de tous les comptes reste inchangé après un transfert. Par exemple, si 100 dollars sont transférés d'un compte à l'autre, la somme des soldes des deux comptes reste la même afin de préserver les règles comptables.
- L'isolement L'isolation empêche les transactions d'interférer les unes avec les autres. Lorsque plusieurs transactions sont exécutées simultanément, l'isolation permet de s'assurer qu'elles n'affectent pas les résultats des autres. Chaque transaction doit être isolée pour éviter les conflits, en particulier dans les environnements à forte circulation.
Exemple : Si deux clients tentent d'acheter le dernier article en stock en même temps, l'isolation garantit qu'une seule transaction aboutira et que l'inventaire sera correctement mis à jour pour refléter le changement.
- Durabilité La durabilité garantit qu'une fois qu'une transaction est terminée, ses modifications sont stockées en permanence dans la base de données (même si le système tombe en panne immédiatement après). Cela permet de garantir que les données restent intactes et accessibles après une panne.
Exemple : Dans un système de commerce électronique, la durabilité garantit que les données de la commande sont enregistrées dans la base de données une fois que le client a effectué son achat. Même si le serveur tombe en panne quelques instants plus tard, l'enregistrement de l'achat reste intact et peut être récupéré lorsque le système est restauré.
Comment l'ACID est mis en œuvre dans les bases de données SQL¶
Les bases de données SQL traditionnelles appliquent les propriétés ACID par le biais de mécanismes de contrôle des transactions tels que les commandes SQL comme BEGIN, COMMIT et ROLLBACK. Ces commandes gèrent les transactions, tandis que les journaux de transactions et les verrous garantissent l'intégrité des données.
Par exemple :
- L'atomicité est gérée à l'aide de ROLLBACK en cas d'erreurs, ce qui permet d'éviter les mises à jour partielles.
- La cohérence est assurée par des contraintes (par exemple, clés étrangères, clés uniques) afin de maintenir l'intégrité des données.
- L'isolation est mise en œuvre au moyen de verrous afin d'éviter les conflits entre les transactions simultanées.
- La durabilité est assurée par la persistance des transactions, garantissant qu'elles ne sont pas perdues une fois validées, même en cas de défaillance.
PostgreSQL : Exploite le protocole WAL (Write-Ahead Logging) pour garantir la durabilité et la cohérence en enregistrant les modifications dans un journal avant de les appliquer à la base de données